Explanation of Barlow Twins Self-Supervised Learning approach my Meta AI
computer-vision
self-supervised-learning
Author
Pramesh Gautam
Published
February 18, 2023
Self-supervised learning (SSL) is the idea of learning representations from data without the use of any data labels. Supervised algorithms in vision normally use Imagenet data where the image labels are used as supervision while training the model. On the other hand, self-supervised approaches are designed in such a way that ground truth labels are not required. This eliminates a lot of careful annotation that needs to be performed by humans. This in turn enables the use of vast amounts of unlabeled data. Normally self-supervised approaches in Computer Vision are based on aligning the features of two different augmentations of a single image.
Figure 1: SSL architecture diagram
The general architecture of self-supervised learning is shown in Figure 1. Here \(T\) is a set of different augmentations that can be composed. \(t^A\) and \(t^B\) are sampled from \(T\) and image \(X\) is transformed using these augmentations. Augmented images are fed to the same neural network \(f\) which generates features \(Z^A\) and \(Z^B\) for transformed images \(X^A\) and \(X^B\) respectively. \(f\) can be a shared network or unshared. The objective of SSL is to make \(Z^A\) and \(Z^B\) similar for pairs of the same image and different across different images. Self-supervised learning is based on this idea.
One thing to be careful of in SSL to prevent collapse i.e the situation where \(Z^A\) and \(Z^B\) are the same for every image. There are various techniques to prevent collapse. Contrastive learning and asymmetric updates are some of those approaches. For a review of self-supervised methods, you can refer to1.
Barlow Twins
In this post, we’ll discuss the paper Barlow Twins2 from Meta AI.
Motivation
Barlow Twins is a method of learning representations without using supervised data i.e. it is a self-supervised learning approach. It tries to overcome the design decisions that were required to prevent collapse in previous SSL methods. Some of those techniques are the use of negative samples, asymmetric learning updates, stop-gradient operation, large batch size, etc. This paper eliminates the need for such choices and achieves results comparable with state-of-the-art methods. This is based on an idea called redundancy reduction which has been borrowed from neuroscience.
Before going into the methods, let’s understand the different types of collapse that can occur. This paper avoids the collapse situations mentioned below.
The first collapse scenario is the one where the model outputs the same features for all the images. In doing so, the features will be the same across augmentations for a single image (which is required) but it will also be the same for all the images (which is not required). One common solution to avoiding this type of collapse is to use negative samples and make the representations of positive samples (views of the same image) closer in feature space and the representations of negative samples (views of other images) far apart. Contrastive learning3 is probably the most famous method to avoid this form of collapse. This form of collapse is shown in Figure 2. In the figure, both the cat and dog images have the same features.
Figure 2: Collapse scenario having same features for all images
The other form of collapse (not exactly a collapse but redundancy) is shown in Figure 3. In this scenario, the features are different across different images and the same for the different views of the same image. This is what we want while learning representations. But the problem is that the features are redundant i.e repetition across multiple dimensions. We want to avoid this case since this adds redundancy and learns nothing significant. In Figure 3, both views of the cat have the same features (required case) but the features have duplicate entries which add redundancy and learn nothing significant.
Figure 3: Collapse scenario having redundant features
Figure 4: Required scenario with redundancy removed
We want the features for different images to be different but the features for different views of the same image to be the same. On top of that, we want the features to avoid redundancy. This is shown in Figure 4. Here the features for the rotated views of the cat’s images are the same but the features in different positions are different i.e. redundancy is avoided. The loss function introduced in Barlow Twins achieves this and we discuss this below.
Architecture
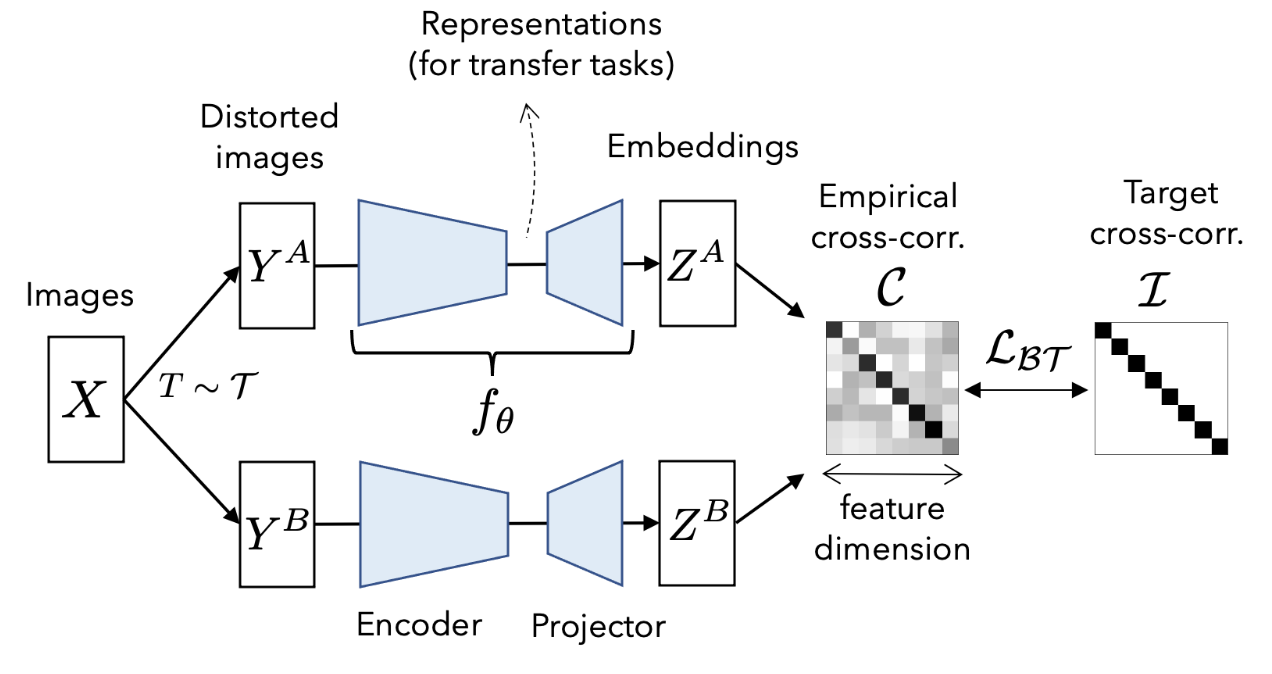
Figure 5: Barlow Twins Architecture
The architecture of Barlow Twins is shown in Figure 5. The objective is to make the features of different augmentations similar with the removal of redundancy and this is achieved by trying to make the cross-correlation matrix of features approach identity. We’ll discuss this in detail in Loss Function.
The loss function used in Barlow Twins is shown in Equation 1. The first part is called invariance term and the second term is called redundancy reduction term. The idea is to make the cross-correlation matrix of features of two views of images close to the identity matrix. When the cross-correlation matrix is close to identity it will cause the features in the same position to be similar and the features in different positions to be different from one another. This is captured in the cross-correlation matrix as the matrix is square and the diagonal elements correspond to the features in the same position and the off-diagonal elements are the correlation between features from different positions.
Going back to Figure 4, the diagonal elements will be 1 if the features in the same position are the same across two feature vectors and the off-diagonal elements will approach 0 as the features from different positions will become different from one another. i.e \(C_{12}\) will be close to 0 when element 1 from the first view’s features and element 2 from the second view’s features are different from one another. This removes redundancy.
Still, there is another form of collapse to remove where features are the same for different images as shown in Figure 3. It can be removed by normalizing the features. This is shown below where features are transformed to 0 when they are the same for different images. If they are 0s then the loss function will get large and the features need to be made different to minimize the loss. The features being 0 are shown below.
/home/pramesh/miniconda3/envs/torch1.12/lib/python3.7/site-packages/torch/cuda/__init__.py:83: UserWarning:
CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW (Triggered internally at /opt/conda/conda-bld/pytorch_1656352496882/work/c10/cuda/CUDAFunctions.cpp:109.)
In this post, we mainly discussed the motivation behind Barlow Twins and the methods that help to achieve what is required. It has been shown in the paper that this method eliminates the need for various collapse prevention techniques that were shown to be required in earlier papers and achieves results comparable to State of the art methods. Please post comments or open pull requests if you have any questions or find anything that needs to be fixed. I’ll see you in the next one. Bye!
References
1.
Jing, L. & Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. (2019) doi:10.48550/ARXIV.1902.06162.
2.
Zbontar, J., Jing, L., Misra, I., LeCun, Y. & Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. (2021) doi:10.48550/ARXIV.2103.03230.
3.
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. (2020) doi:10.48550/ARXIV.2002.05709.